Human Language ModelingusingHaRT: Human-aware Recurrent Transformers
Language Modeling as a task grounded in the "natural" generators of language, people.
Objective
To model the probability of the next word w {t,i} in the current document t based on past words w {t,1:i-1} in the document and a user state U {1:t-1}
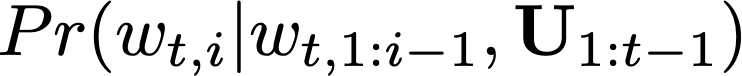

Background
Language modeling is fundamental to NLP, with many large transformer based models becoming widespread.
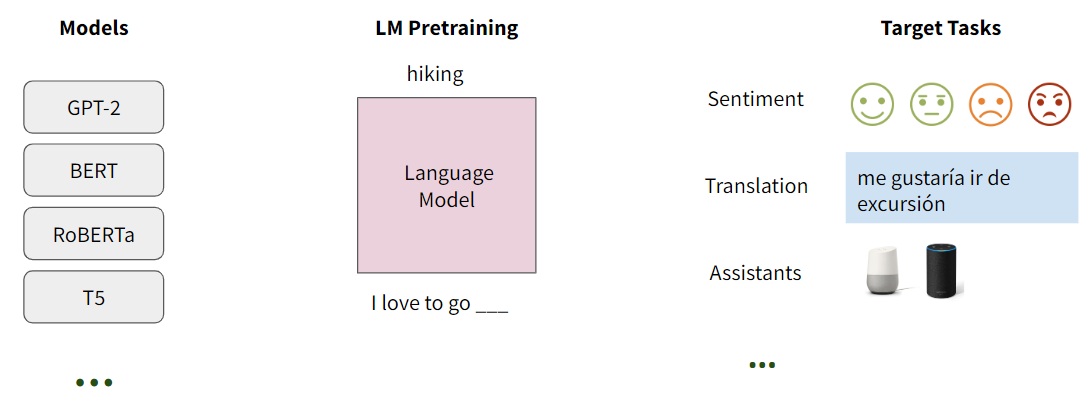
So, What's missing?
Large language models treat dependent inputs as independent even when they are not.
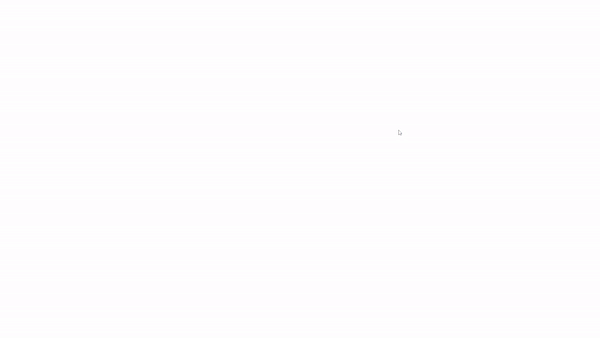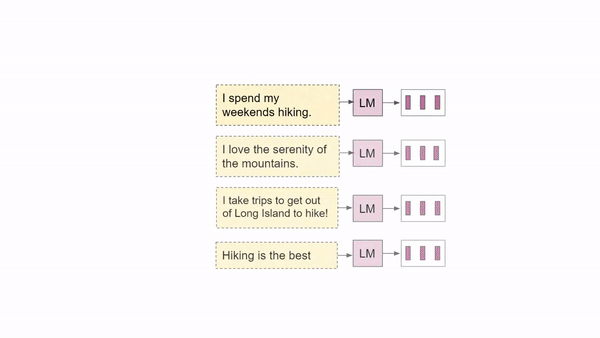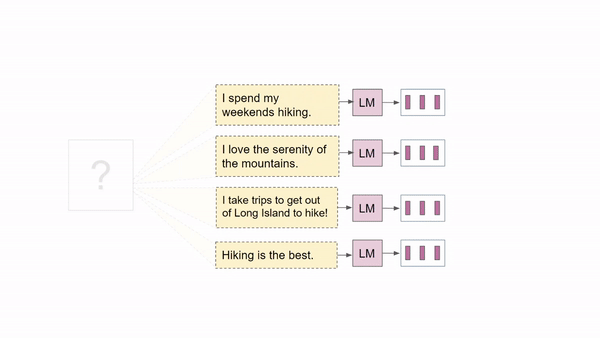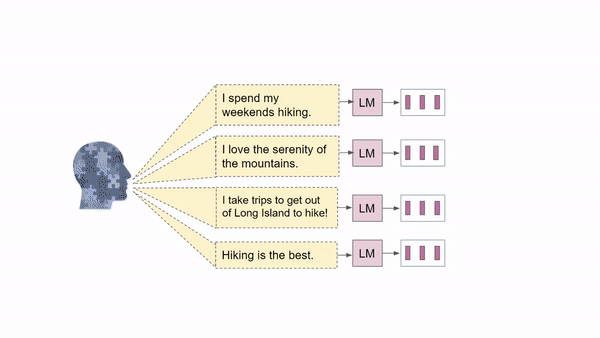

Task: Human Language Modeling (HuLM)
To address the above gaps, we propose Human Language Modeling (HuLM), a language modeling task grounded in the "natural" generators of language, people.
Building from the traditional language task, that is
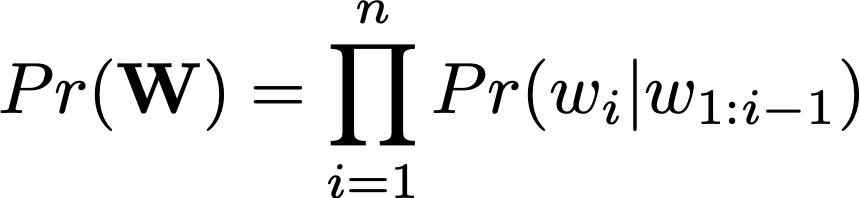
In HuLM, we also condition on a user state
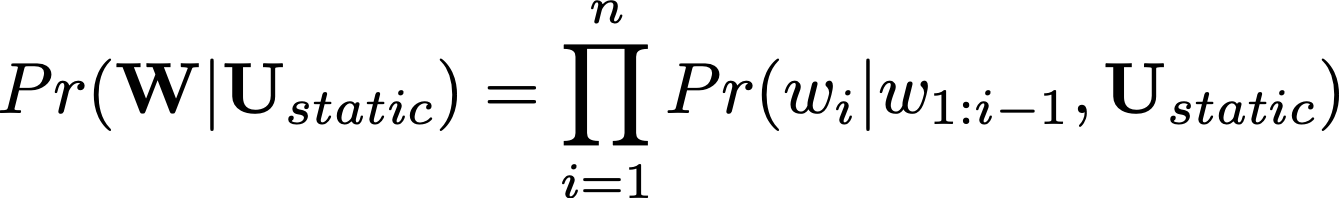
But, human states are somewhat stable but not entirely static.
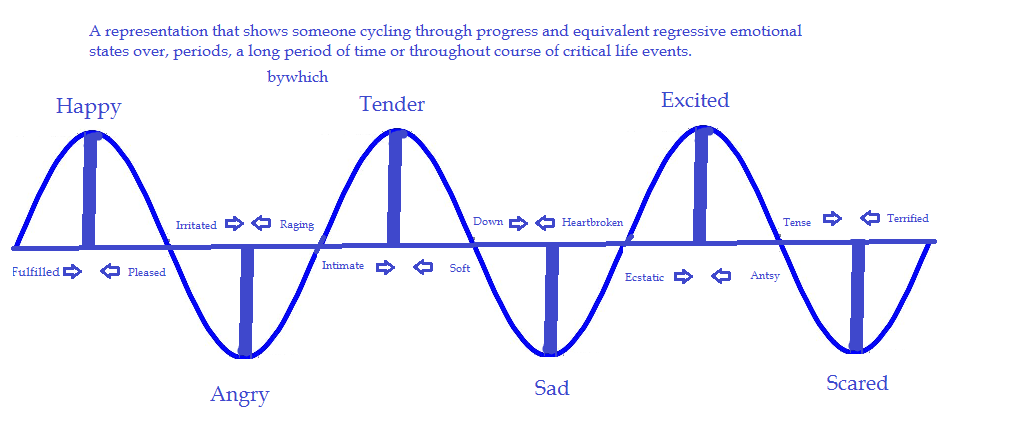
(Washington Outsider, 2014)
To account for this, we condition on a dynamic user state:
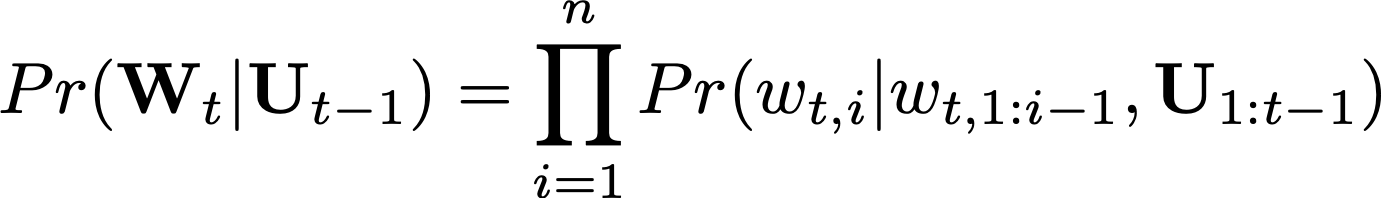
Method: Human-aware Recurrent Transformer (HaRT)
To address HuLM, we introduce HaRT: Human-aware Recurrent Transformer, an auto-regressive transformer with a recurrent user state. HaRT builds on the recurrent Transformer approaches from Yoshida et al., 2020 and Transformer-XL ( Dai et al., 2019).
Pre-training
We pre-train HaRT for the HuLM task on two datsets
State-of-the-Art Results
For comparison, we evaluate HaRTTwt on the language modeling task (over test data from the paper and Twitter-only test data) and document-level fine-tuning task. HaRTTwt has a slight difference in the results but is in alignment with the full HaRT model (pre-trained on HLC). HaRTTwt training and evaluations were run on two DGX A100 GPUs.
Language Model Perplexity
| Model | Test HLC (ppl) | Test Twt (ppl) |
|---|---|---|
GPT-2 frozen | 116.35 | 144.67 |
GPT-2 HLC | 48.51 | 39.93 |
HaRT Twt | 33.15 | 23.76 |
| HaRT | 26.11 | 24.70 |
Document-level Downstream Tasks
| Model | Stance (F1) | Sentiment (F1) |
|---|---|---|
GPT-2 HLC | 68.60 | 76.75 |
HaRT Twt | 70.53 | 77.01 |
| HaRT | 71.10 | 78.25 |